
The AI Engineer's path
Transferable lessons from ML Engineering

“What do you do?” evokes a lot of unresolved emotion. I envy people who have the luxury of a few syllables to encapsulate their contribution to the world. Doctor, Mechanic, Bureaucrat, Software developer. must be nice.
I have been called a “Quant,” “Number Cruncher“, “data analyst,” “Data Scientist,” “Machine Learning Engineer,” and most recently, “Machine Learning Scientist.” “AI scientist” is creeping up just around the corner. It’s a good thing people in ML don’t seem to have a thing for tattooing their professions.

Now, almost 10 years in, I don’t even bother to find out what the newest sexy title is. In my head, I’ve always been doing the same thing - making fun stuff with data. But that won’t fly with my wife. She needs to tell her older relatives what her husband does for a living. I’ve never given her a straight answer and instead try to explain to her the dynamic nature of the industry and how it is still early to pigeonhole people into titles. She is having none of it, though, and has vengefully started introducing me as an “Artificial Scientist,” which gets a few laughs but also precludes further inquiry. So win-win.
The tectonic forces of change
This waltz with titles hasn’t been without reason. What it takes to deploy intelligent software has changed beyond recognition. A couple of decades ago, only a few would dare to call themselves data scientists. To be allowed to do what data scientists do today, you would have arcane knowledge of linear algebra, statistics, and a PhD to boot.
All the wobbliness on the surface of the data world has originated from two tectonic forces:
a) the packaging of knowledge into high-level tools and,
b) the democratization of access to these tools.
Twelve years ago, it took me a semester to fit a Hidden Markov Model using MATLAB for my speech processing course. MATLAB, for the uninitiated, is a scientific computing tool and language that is expensive enough that most of you wouldn’t have had the luxury to use it. Good thing I was part of an institution that paid for it, and I had plenty of time to learn its peculiar code syntax. Seven years ago, I moved to R, which is an open-source language built to aid data analysis and modelling. It is much better than MATLAB, and has much better tooling. But R focuses on conventional statistical methods and doesn’t do so well at anything else. I soon switched to Python, which is a more comprehensive language, and you could, in theory, do anything that you did in R (although with a significant loss of elegance when it came to data analysis).
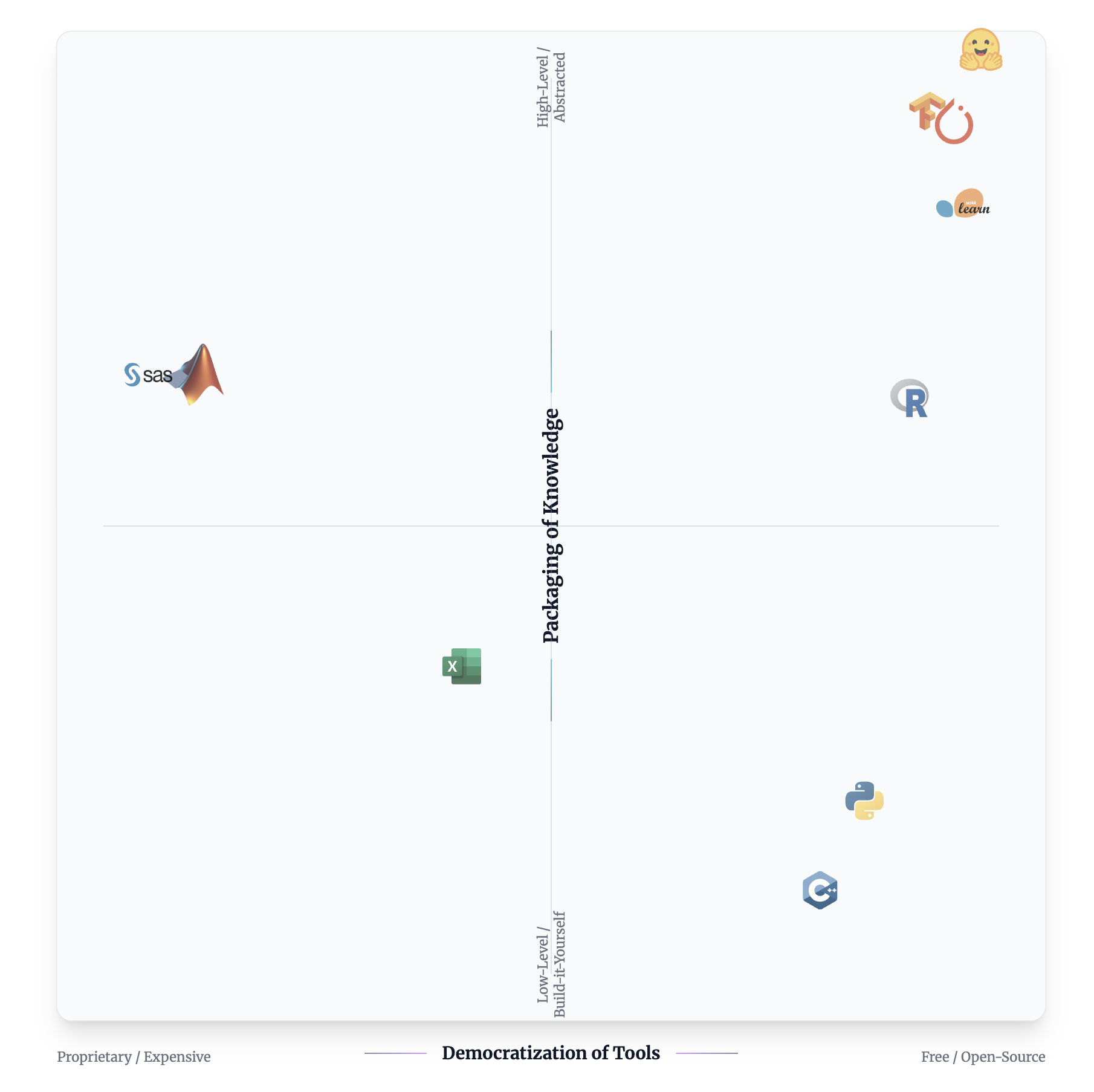
With Python tooling today, anyone with common sense and a grasp of the language can fit and deploy models. With the rise of deep learning to dominance this past decade, Pytorch, a deep learning framework in Python, has become THE framework for deep learning. This has cemented Python's status as the only language you'd bother with when working on ML. Over time, PyTorch has automated much of the insider knowledge required to train large, robust Deep learning models. Knowledge that had previously been locked behind university research labs and big tech offices in SF.
“Deep learning is often viewed as the exclusive domain of math PhDs and big tech companies. But as this hands-on guide demonstrates, programmers comfortable with Python can achieve impressive results in deep learning with little math background, small amounts of data, and minimal code.”
- Jeremy Howard’s intro to his book Deep Learning for Coders which I strongly recommend
The gates of Machine learning have been opening, and more of us, without PhDs and access to expensive tools, have started training and deploying models.
The promised land

This trend of democratization and packaging has reached an extreme today. Today, you can use pre-trained foundation models using an API and tweak them for your task using English; all you need as a developer is a bunch of glue code to put everything together, and voila, you’ve tamed AI! Every day, AI products are being delivered by people with no previous ML experience. Experienced developers will ride this newest wave of democratization to become AI engineers, increasing the speed at which AI can reach the real world.
But they’ll need to adapt to the new reality of this new kind of software, what Karpathy calls Software 3.0. Karpathy divides software into three categories: Software 1.0, where developers painstakingly write explicit instructions line by line; Software 2.0, where Machine learning engineers train neural networks by feeding them data(my day job); and Software 3.0, our brave new world, where AI Engineers program pre-trained models in English.
On the face of it, Software 3.0 looks the same as Software 1.0 - just a bunch of code, a few API calls with some prompts added in. But the biggest differences lie beyond code. They always have in Machine learning. Adapting to these differences will separate Sotware 1.0 engineers who become great AI engineers form the rest.
What does it take to deploy Software 3.0?
Shyam is an exceptional backend engineer an a popular e-commerce platform. Writing APIs, debugging distributed systems, ensuring consistent uptime - he has done it all. AI engineering looked fun and not too different from what he was already doing.
When a proposal came in to build a sentiment classifier to filter out products receiving overwhelmingly negative reviews - he readily volunteered. How hard could it be? In no time, armed with OpenAI API credits and a simple prompt, Shyam had an endpoint running. He quickly checked a few reviews. Negative review: blocked. Positive review: passed. It looked great, and he proudly demoed it and deployed it to production. Everyone was happy, news went up to the board that the company was now AI-powered.
Initially, things ran smoothly. The API worked flawlessly, latency was low, and all integration tests were green. The first few days Shyam would look at the negatively flagged reviews himself to see if they were accurately labeled. It seemed to be working so well that he stopped doing that. Shyam had unknowingly stepped into a trap unique to machine learning.
Over the next few weeks, unnoticed, something began to shift. A new wave of teenage customers started reviewing sports gear, using slang like "sick" or "crazy" to mean "excellent" or "impressive." The OpenAPI model, trained on older text data, interpreted these expressions negatively. Product after product was blocked from the site due to "negative" reviews.
The CEO sent a panicked message: "Why are so many popular products suddenly disappearing from our listings in the sports segment? Sales are tanking!"
Shyam was flummoxed. His API was responsive. Infrastructure checks passed. Logs showed no errors. Yet something was broken. His conventional software instincts couldn't immediately detect the issue.
In Software 1.0, there is little ambiguity in either the feasibility of the solution or its correctness once it is implemented. In fact, many of us write tests to check correctness even before implementing the solution - an approach called test-driven development.
Once you settle on a solution, the code you write as part of the solution explicitly instructs the machine on what to do. The code itself is intelligible and deterministic. If it fails, you can point to the lines that caused the failure. Sometimes failures occur not because of the code but the environment it is run in - the os, package versions, network access, etc. This dissonance in dev/prod environments gives rise to the “works of my machine” meme. If you maintain consistency between your dev and prod environments, you can mitigate these errors.
Failures will still happen, though; you’re probably not moving fast enough if they aren’t. As harrowing as failures in production are, most of them can be quickly fixed if you set up good observability and logging.
Entering the world of Software 3.0.
The first major change is that it is nearly impossible to assess the feasibility of a solution from the start. Many ideas seem promising in the chat window, but they wouldn't work in production when applied to real user data. It's also difficult to verify whether a solution is correct. A model with 60% accuracy might sometimes be correct because there's no better option (e.g., stock price movement prediction). Other times, a model trained with buggy code might still achieve 90% accuracy simply because the problem is easy (e.g., distinguishing cats from dogs). The properly trained model would have reached 99%. Software 3.0 development relies on experimentation, benchmarks, and metrics.
Second, there are very few explicit instructions. It would be a paradox if there were a lot of them, since the point of machine learning is for the “machine” to “learn” instructions. Instructions are “learned” at training time via training code and data, and are then stored as sacred vectors of floating-point numbers, aka weights that no human can interpret. The OpenAI API you use is a wrapper around these weights stored in their databases. Forget understanding them; most times, you won’t even have access to them.
Third, the “environment” that you need to stay consistent between dev and prod is now not just the OS version, package versions, etc. Your dev environment is the state of the world as depicted by the training data, and the prod environment is the world where people use your model. Any divergence leads to what ML people call “drift”. Drift is unlike Software 1.0 environment mismatch problems. It is more subtle, slippery enough to escape traditional observability tools, and hard to do an RCA on and fix.
This brings us to the last, and possibly biggest hit: almost all machine learning failures are silent. Here is an excerpt from a great paper Google wrote on ML tech debt -
Unit testing of individual components and end-to-end tests of running systems are valuable, but in the face of a changing world such tests are not sufficient to provide evidence that a system is working as intended. Comprehensive live monitoring of system behavior in real time combined with automated response is critical for long-term system reliability. The key question is: what to monitor? Testable invariants are not always obvious given that many ML systems are intended to adapt over time.
- Hidden Technical Debt in Machine Learning Systems
It was these subtle differences that tripped Shyam up, but he need not be embarrassed; he's in good company.
Zillow used its Zestimate model to buy homes at scale. When post-lock-down demand cooled and contractor bottlenecks emerged, the model kept assuming a hot, rising market and systematically over-bid: Zillow wrote down >$500 million, halted iBuying, and laid off 25 % of staff. Analysts traced the root cause to concept drift in the housing-price relationship that the model hadn’t been retrained to capture.
Google’s model mapped 45 flu-related search terms to CDC case counts and, for a few years, looked brilliant. But in the 2012-13 season the model over-predicted U.S. flu prevalence by ~140 %.
Why it drifted - Autocomplete and “related searches” nudged people toward the model’s keywords, inflating signals that once correlated with illness. Media coverage of influenza changed what healthy people searched for, but the model still treated every search as evidence of sickness.Google kept the mapping static; no online learning, no recalibration.
Result: the poster-child of “big data epidemiology” was quietly shut down in 2015, becoming a textbook cautionary tale.
ML failures are shy. They don’t announce themselves as loudly as traditional software failures do. Machine learning engineers need to look out into the world to evaluate what might violate their dev/prod environment consistency. It would be unfair to expect backend, frontend, or infrastructure engineers to understand how a housing market crisis or flu patterns affect their systems. But this is a standard expectation from ML Engineers.

Parting words
While tools and technologies will continue to evolve, the awareness of the assumptions made during model training, the ability to detect subtle divergences from these assumptions, and the knowledge of how to mitigate them will continue to set apart successful AI Engineers.
Although the expertise and resources needed to train and/or deploy models to production have exponentially decayed, this other stuff remains as important as ever and is often only learned through experience. The good news is you don’t need to be trained in ML to have these abilities. I know a ton of non-ML folks who have them. I know a few ML professionals who don’t.
The best way I’ve found to develop these abilities is to try to solve a problem using ML and see what it takes for it to remain solved. Go beyond the demo. In ML, ten solutions can solve a given problem at a point in time. They will look the same at the start. Only two of them are robust enough to still be working two years down the line because they make better assumptions, are easier to debug, and support iterative development.
Another thing that works well is prayer. I’ll leave you with one that I’ve found a lot of comfort in, and I hope it'll bring you comfort on your journey to AGI.
God, grant me the power to build and deploy models, the clarity to detect when they're off-track, and the wisdom to understand why. Amen.