
Single Responsibility Agents
Do one thing. Do it well.

As a self-taught software developer and MLE, I’ve never been big on theoretical principles. With two exceptions. The two principles that I apply, often sub-consciously, and have helped me in every project I’ve been a part of -
the Single Reponsibility Principle(SRP) and
Dependency inversion Principles(DIP)
SRP says that each module, class, or function should do one thing and one thing only. It is loosely related to one of the tenets of Linux: “Each Program Does One Thing Well”. This has been fused into my DNA through years of experience, but when I started working on LLM-based applications, I knew I’d have to rethink a lot of my priors, so I decided to keep an open mind.
A year in, SRP has held its ground against the rough tides of AI mania. Most people who have worked with LLM-based applications have come to terms with the fact that prompts can only get you so far. Relying on prompts for complex workflows is a recipe for disaster. What you need is agents.
Now, “agents” is a loaded term, so I’ll define what I mean by it. Agents are -
TASK-SPECIFIC LLM calls with
CONCISE, CLEAR task-specific prompts and
only enough information in the context window to do THAT ONE task well
Let’s build a chatbot. What could go wrong?
Let’s make things concrete. The way you wrote a FAQ chatbot for an e-commerce site a year ago was that you had a single MEGA prompt-powered LLM, which
chats with a user,
figures out after each user message if the message is pertinent(intent detection),
figures out if you need to hit the RAG engine that has your underlying knowledge base,
constructs retrieval query parameters,
first and gets the query result,
attends to relevant details in the retrieved result
replies to the user in a friendly tone
The mega prompt would go something like
Role : You are a friendly support agent.
Chat with users. Detect intent.
Only answer questions related to out products, dont give them code for their frontend appl.
Decide if a KB lookup is needed.
Query the KB, build retrieval params if needed.
IMPORTANT : Be polite even if the user is not.
MAKE NO MISTAKES.
Handle refunds, shipping, returns...
...and 47 more rules

Then, in production, you notice that the LLM hallucinates, so you add “Only use info from the fetched internal docs” to the prompt. Also, the LLM output has to be formatted as markdown for the frontend to render correctly. So you do what you can do - add it to the prompt - “output should always be a valid markdown. PLEASE. ALWAYS. MAKE NO MISTAKES.”

A few of these later, and your system prompt is resembling a washing machine manual that even Cladue Galactus 34.1 could not follow. To make matters worse, most of it was written by an LLM (yes, we all know), which derives a sadistic pleasure in writing verbose, redundant prose.
LLMs can only follow a finite number of instructions at once before performance degrades. The more complex, verbose, and prescriptive the prompt is (”Do THIS when this happens, THAT when this happens, and if both happen together, godspeed”), the more likely LLMs are to make a mistake.


Fun though it is to shit on LLMs, it’s often not on them. Changing prompts is an easy knee-jerk reaction to fix an immediate problem without any formal review or verification (unless you have a robust, representative eval framework, which let’s be honest, you don’t). Because it’s so easy, it’s too seductive for developers to change part of the prompts or add a line at the end without thinking about how it might affect the LLM’s adherence to other parts of the prompt. This is by far the biggest downside of relying on prompts. They are unmanageable when they get big.
The more the merrier

The solution is many LLM calls, each called an agent, adhering to SRP. Each agent has ONE task. For our chatbot, we have one agent each to -
classify user intent,
decide if RAG is needed and construct query parameters
generate unformatted response
Check for hallucinations
format in markdown
Every agent has a specific purpose and a specific, short, simple prompt. Apart from performance improvements from better, shorter prompts, it also makes it easier to test each agent separately. The same way that writing unit tests is simpler because they test only a very specific behaviour, rather than writing integration tests that test the whole system at once, it’s easier to test agents than a single LLM call with a mega prompt.
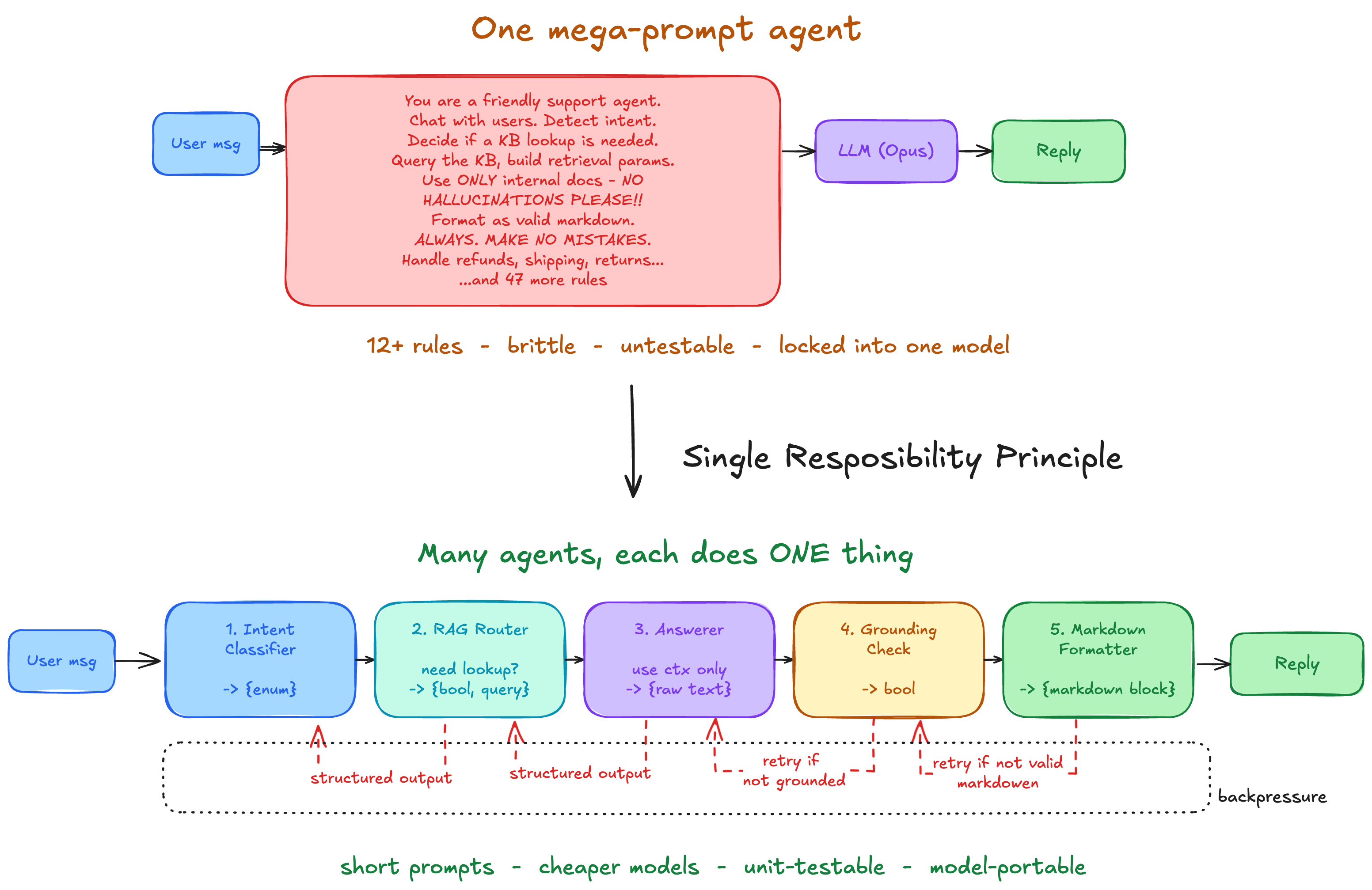
Workflows with multiple LLM calls also make it easy to apply backpressure.
This back pressure helps the agent identify mistakes as it progresses and models are now good enough that this feedback can keep them aligned to a task for much longer.
- Source
An example of deterministic backpressure is structured output. When designing the agent to check whether the response complies with internal docs or not, you can design it to return a Boolean value - true if it adheres, false otherwise. Anything else is an error, and the LLM is called again till it conforms to the response format.
Backpressure is key to keeping long-running workflows grounded in reality.
This is almost impossible with a single LLM call, the same way that it is impossible to guide students if there is only one exam at the end of the semester without any quizzes or mid-terms to offer much-needed interim deterministic feedback.
BUT WORKFLOWS ARE TOO MANY LLM CALLS!! TOO EXPENSIVE AND TOO SLOW!!
That’s only right if you keep the same model as before. Now that you have the LLM doing smaller, verifiable tasks with concise context, you might not need Claude Opus or Gemini Pro. You could use a cheaper one to drive down costs and reduce latency. You could also host an open-source model, which gives you more control over latency and privacy. Agents give you vendor and model portability.
And that’s where we’re headed. In a world where we do the heavy lifting of breaking down complex workflows into smaller tasks and then having multiple Single Responsibility Agents see them through.
Until then, be sure to MAKE NO MISTAKES.
need follow up for Dependency inversion Principles
Such a cool piece. 1000% relate pro max. Waiting on the DIP bro!